Voynich Manuscript - Basic Analyses
Sarah Goslee
2006-10-22
1 Introduction
I am working from a modified EVA transcription of the VMS (Reeds/Landini's interlinear file in EVA, version 1.6e6 - http://www.ic.unicamp.br/ stolfi/voynich/98-12-28-interln16e6/). Starting with that file, I constructed a consensus version, and I've fixed some apparent transcription errors by comparing the transcription with the high-resolution SIDs available courtesy of the Beinecke Rare Book and Manuscript Library of Yale University, current owners of the manuscript. (I downloaded them from the links available at www.voynich.nu.)
I've also made some other changes to match my conception of the symbol set (in no
particular order):
- ch -> c because I think the c-ligature-c combination is one character.
- sh -> C I'm not sure of the meaning of the c-ligatureswirl-c - it seems to behave
very much like the regular c - but am keeping it separate.
- paragraph initial gallows (fkpt) -> capitals FKPT - I think these have
some other meaning and are not part of the following word.
- All possible word breaks (,) have been marked as definite word breaks (.). I'm
continuing to check these as I proofread the transcription.
- = used to mark paragraph / label beginnings and endings, and - used to mark
other line beginning and endings.
- Internal - marking intruding images have been replaced with word breaks (.)
- I've üntangled" the ch-gallows combinations, putting the gallows letter first.
I think they are scribal conceits, and this idea is supported by the appearance of
gallows-ch combinations at the beginning of paragraphs.
- "weirdos" are all denoted by X
A complete list of changes suitable for running as a source file in vim is contained in appendix 1.
2 Ordination
First, I looked at overall pattern of character frequencies (Fig.
1) and word frequencies (Fig.
2)
between Currier languages and section types, using principal coordinates ordination on
Euclidean distances of row-standardized frequencies. Labeling the same ordinations with
section types as well as Currier language (Figs.
3,
4) showed
that the language groups separate for both character and word frequencies (although not cleanly),
but that thematic (topical(?) section) groups separate more clearly for word frequencies. This suggests to
me that character frequency is determined by A/B ëncoding", while word frequencies are more
closely related to theme.
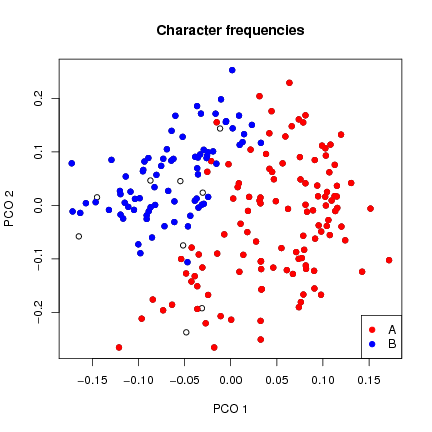 Figure 1: Ordination of character frequencies in Currier A and Currier B pages (paragraph text only).
Figure 1: Ordination of character frequencies in Currier A and Currier B pages (paragraph text only).
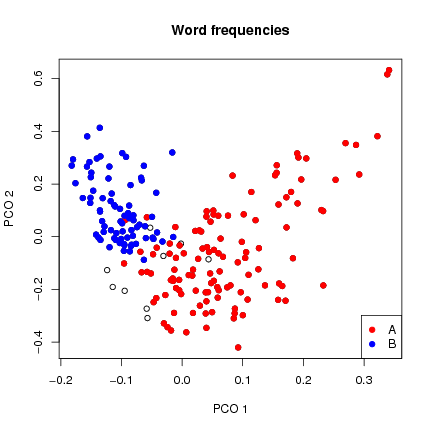 Figure 2: Ordination of word frequencies in Currier A and Currier B pages (paragraph text only).
Figure 2: Ordination of word frequencies in Currier A and Currier B pages (paragraph text only).
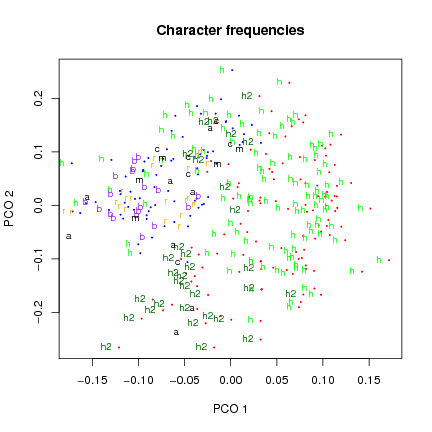 Figure 3: Ordination of character frequencies labeled by section and Currier language (paragraph text only).
Figure 3: Ordination of character frequencies labeled by section and Currier language (paragraph text only).
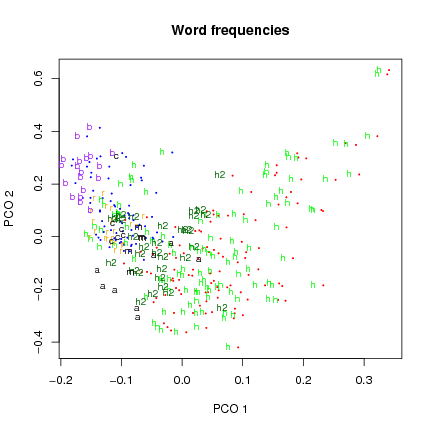 Figure 4: Ordination of word frequencies labeled by section and Currier language (paragraph text only).
Figure 4: Ordination of word frequencies labeled by section and Currier language (paragraph text only).
3 Analysis of Distinct Subsets
I've decided to concentrate my initial analyses on three subsets of data chosen to be distinct based
on supposed content and on separation in the ordination diagrams (especially word frequencies).
Set R is the recipe section, set B is the balneological section, and
Set H is the herbal section in the right tail of the word-frequency PCO. This
gives two thematically-different sections in language B, and only one in
language A. These groups are shown overlaid on the character ordination (Fig.
5) and the word
ordination (Fig.
6).
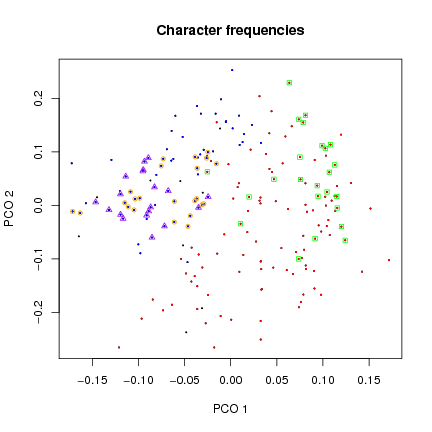 Figure 5: Ordination of character frequencies with group membership superimposed.
Figure 5: Ordination of character frequencies with group membership superimposed.
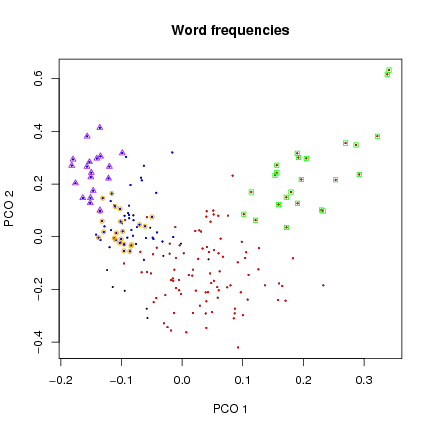 Figure 6: Ordination of word frequencies with group membership superimposed.
Figure 6: Ordination of word frequencies with group membership superimposed.
As suggested by the ordination diagram, the character distribution is very similar in sets
B and R (Fig.
7). Set H differs in its frequencies of c and e, and also o, t and V.
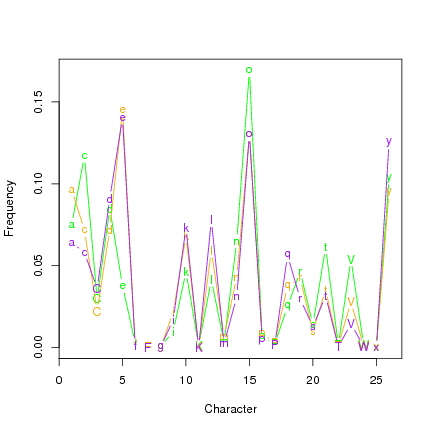 Figure 7: Character distribution in the three chosen subsets.
Figure 7: Character distribution in the three chosen subsets.
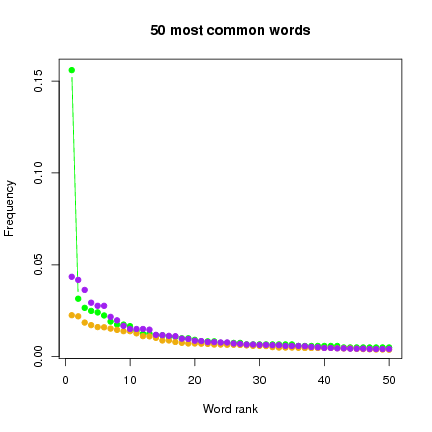 Figure 8: Word frequencies in the three chosen subsets.
Figure 8: Word frequencies in the three chosen subsets.
Word frequency distribution is extremely skewed in set H, with
daVn being extremely common (Fig.
8). Neither set R nor set B show such an extreme pattern.
The ten most common words in set H (by percent occurrence):
daVn col cor dain dy tcy qotcy Co s tcor
16 3 3 2 2 2 2 2 2 2
The ten most common words in set R:
cedy aVn qokeey ar al qokeedy daVn cey Cedy qokaVn
2 2 2 2 2 2 2 1 1 1
The ten most common words in set B:
ol Cedy cedy qokedy qokain qokeedy qol qokal Cey cey
4 4 4 3 3 3 2 2 2 2
The mean word length is slightly greater in set R than in set H (4.7 vs 4.0; Table
1).
The mean number of times a word occurs is different among the groups as well - lowest in H, highest in
B, with R having an intermediate position. The percentage of words appearing only once is similar in sets H
and R, and a bit higher in set B.
| Pages | Chars | Word occ. | Word length | Words | N occ. | Pct. Unique Words |
| H | 24 | 6817 | 1686 | 4.0 | 685 | 2.5 | 30 |
| R | 23 | 50203 | 10746 | 4.7 | 3193 | 3.4 | 30 |
| B | 19 | 27738 | 6236 | 4.4 | 1413 | 4.4 | 35 |
Table 1: Subset Characteristics
4 Appendix 1: Changes to EVA 2006-09-13
%s/!\+//g
%s/,/\./g
%s/ch/c/g
%s/sh/C/g
%s/iiii/VV/g
%s/iii/W/g
%s/ii/V/g
%s/cfh/fc/g
%s/ckh/kc/g
%s/cph/pc/g
%s/cth/tc/g
%s/\.\+/\./g
%s/ \+/ -/
gg
s/-/=/
# don't have a good way to do the next step
# currently, alternate
# /=$
# map <F2> j^f^Ilr=
%s/=f\(.*\)-/=F\1-/
%s/=k\(.*\)-/=K\1-/
%s/=p\(.*\)-/=P\1-/
%s/=t\(.*\)-/=T\1-/
g/%/d
%s/{.\{-}}/X/g
%s/h//g
%s/-/\./g
%s/ \./ -/
%s/\.$/-/
%s/f\([0-9]\)\([rv]\)/f00\1\2/
%s/f\([0-9][0-9]\)\([rv]\)/f0\1\2/